-
Type:
Bug/Issue
-
Resolution: Resolved
-
Priority:
 Critical
Critical
-
CMS165v8/NQFna
-
Cypress v5.4.2
We are implementing eCQM update year 2020 in our application.
After implementing changes for CMS165v8 measure, we have performed (C2 + C3) test using Cypress v5.4.2 (2019.2.0 bundle).
As per cypress, count for IPOP population is 24, but after importing QRDA1 zip(kindly see the attachment) file, our application displays counts for IPOP as 26.
While looking into the problem we have observed a few things mentioned in below scenarios,
**
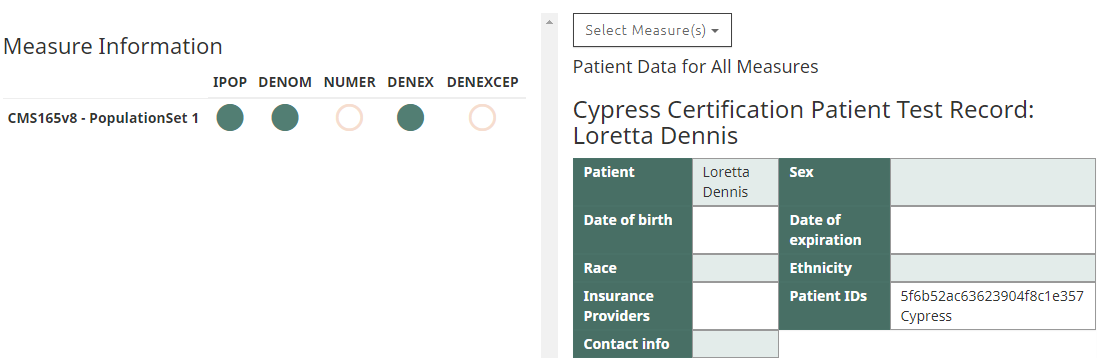
1) QRDA1 zip file contains patient's xml of : Lorie Dennis & Loretta Dennis.
As per cypress report, only "Loretta Dennis" patient data should get considered. (kindly see the attachment)
Now, when you look at the xml file data for both patients, you will find Demographic details(like Date of birth, Gender, Race & Ethnicity) and other Patient data are the same for both patients.
Observation: Except the Patient Name, both patients have almost the same data.
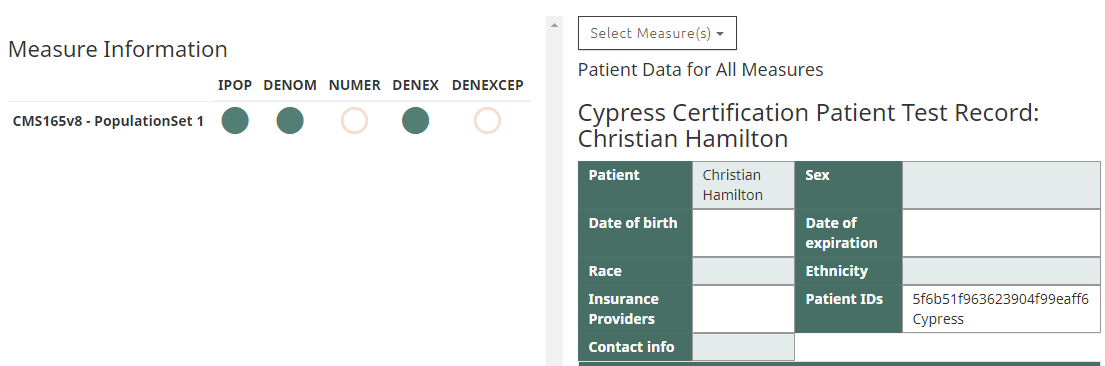
2) QRDA1 zip file contains patient's xml of : Chris Hamilton & Christian Hamilton.
As per cypress report, only "Christian Hamilton" patient data should be considered. (kindly see the attachment)
Now, when you look at the xml file data for both patients, you will find Demographic details(Date of birth, Gender & Race) and other Patient data are the same for both xml.
Observation: Except the Patient Name & Ethnicity, both patients have almost the same data.
Concern : As mentioned in above cases and considering many other demographic details, what would be the closest criteria to be considered to identify duplicate patients?
Also, while other measures testing, we have observed similar kinds of scenarios where only "Patient Names" are different & all the information are the same except (Date of Birth OR Race OR Ethnicity).
Can you please provide us any document or implementation guide link which will help us implement logic to identify duplicate patients while importing QRDA1 Zip files.
Thanks in advance.